InfoWorld’s 2018 Technology of the Year Award winners
InfoWorld editors and reviewers pick the year’s best software development, cloud computing, data analytics, and machine learning tools



























1. 2018 Technology of the Year Awards
Was 2017 really the year of machine learning and AI? Some of us thought it was the year of Kubernetes, or Kotlin, or Vue.js. Or the year of the global cloud database, the progressive web app, or lightweight JavaScript. It might have been the year that hell froze over, considering Linux became available in the Windows Store.
The Technology of the Year Awards are InfoWorld’s annual celebration of the best and most innovative hardware and software on the technology landscape. You will find all of the above and much more among our 2018 winners. Read on to learn about our favorite developer and devops tools, databases, cloud infrastructure, big data platforms, and yes, machine learning and deep learning libraries.
See also:
Technology of the Year 2018: The best hardware, software, and cloud services
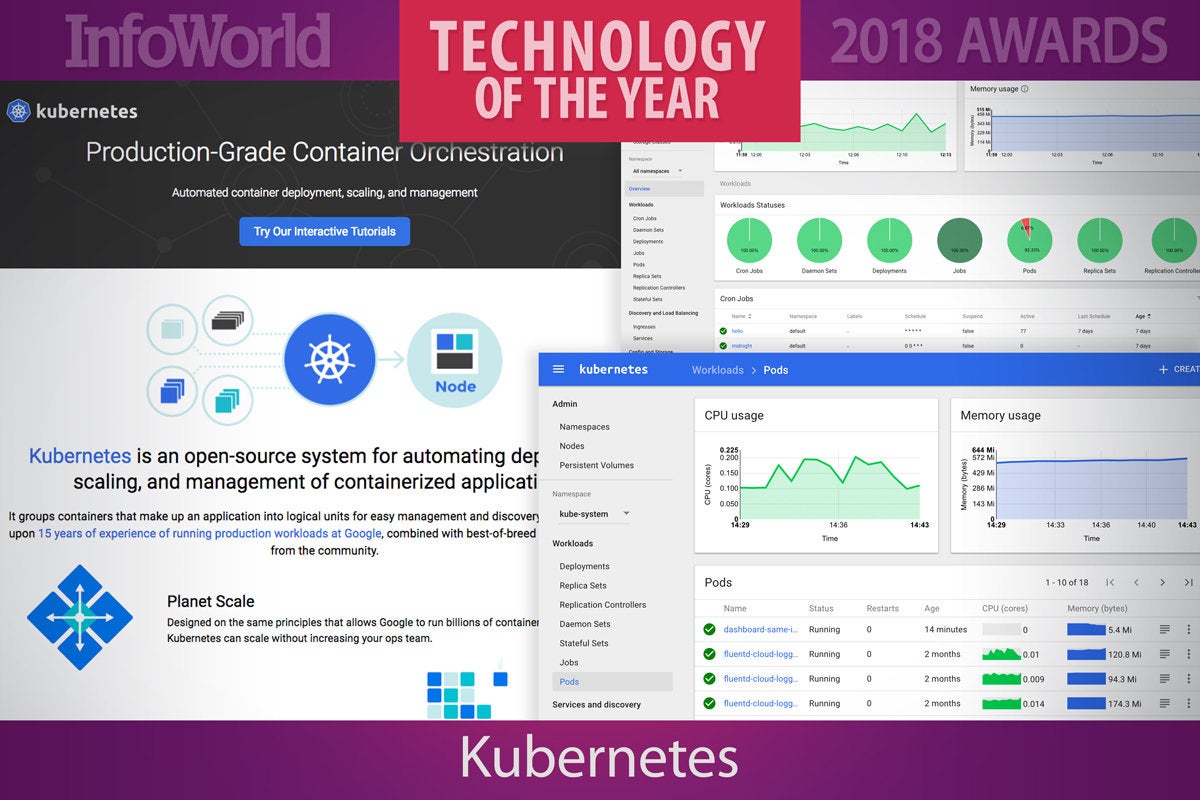
2. Kubernetes
Docker made containers a mainstream development and deployment phenomenon, but Kubernetes has achieved something even greater—making containers manageable. Kubernetes began 2017 as one of many ways to do container orchestration and ended the year as the way, with even former arch-rivals Docker and Amazon climbing on the K8s bandwagon. Kubernetes is now the de facto standard for running containers on-premises and in the public cloud.
Three feature-packed releases over the course of 2017 helped to drive the skyrocketing adoption. Version 1.6 allowed Kubernetes clusters to scale to 5,000 nodes. Version 1.7 bolstered features for extensibility, secrets management, and persistent state in Kubernetes applications. Version 1.8 added role-based access control features, volume snapshotting and resizing, and new APIs to manage workloads. Version 1.9 marked beta support for Windows Server.
Supporting projects added fuel to the fire. Pivotal and VMware teamed up to deploy Kubernetes on VMware vSphere. Heptio, a startup co-founded by Kubernetes creators, took aim at easing Kubernetes setup. Expect 2018 to bring an expansion of Windows support, much-needed improvements to the available storage options, and Kubernetes continuing to consolidate its position as the established choice for container orchestration.
— Serdar Yegulalp
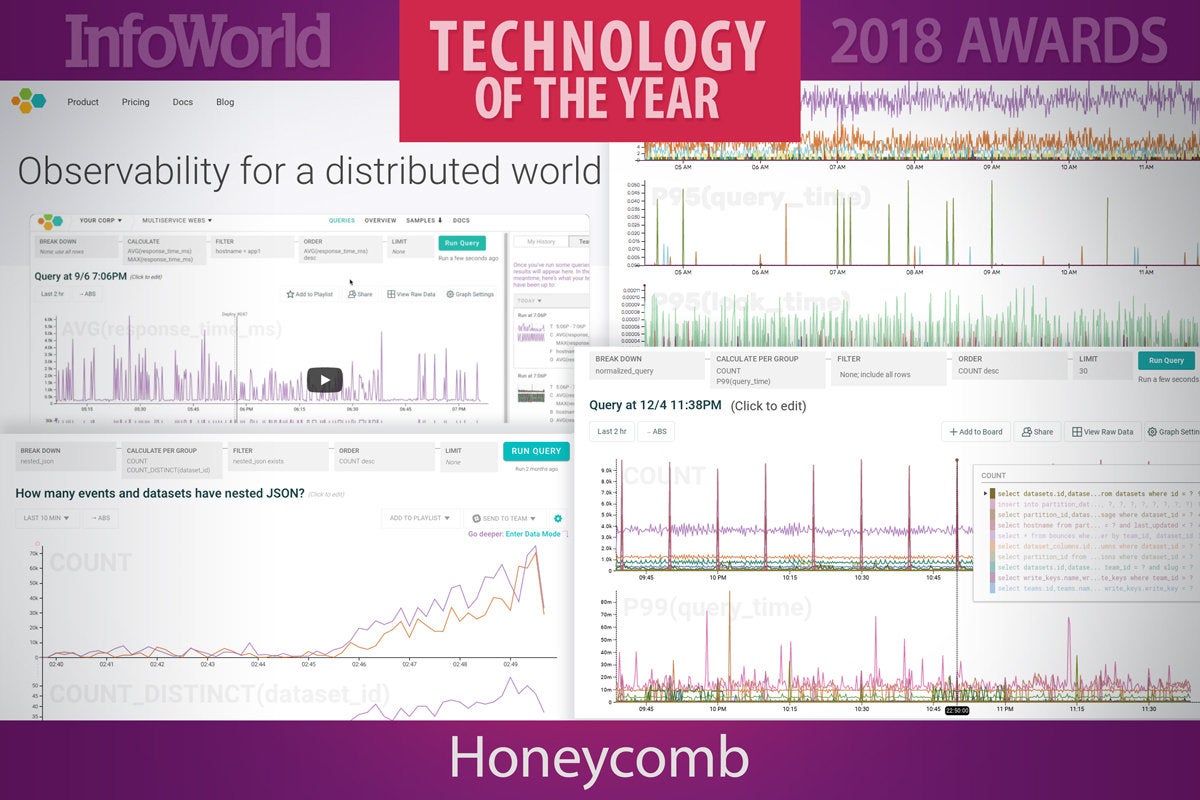
3. Honeycomb
Honeycomb is not a monitoring service. Honest. It is an observability tool for the new generation of distributed applications, where problems are likely to stem from multiple issues in different subsystems. The founders of the company were behind Facebook’s internal Scuba tool that revolutionized internal debugging.
Because you can’t know in advance what information you’ll need at 3 a.m., Honeycomb allows you to do extensive system analysis across almost any axis. The platform is built to handle high-cardinality data like user IDs, which most debugging tools will struggle with.
Honeycomb and its approach to observability are going to become a lot more popular in 2018. Even if you don’t end up using the service, you will want to tune into the Honeycomb blog, which provides a wealth of information for state-of-the-art instrumentation of today’s complex distributed applications.
— Ian Pointer
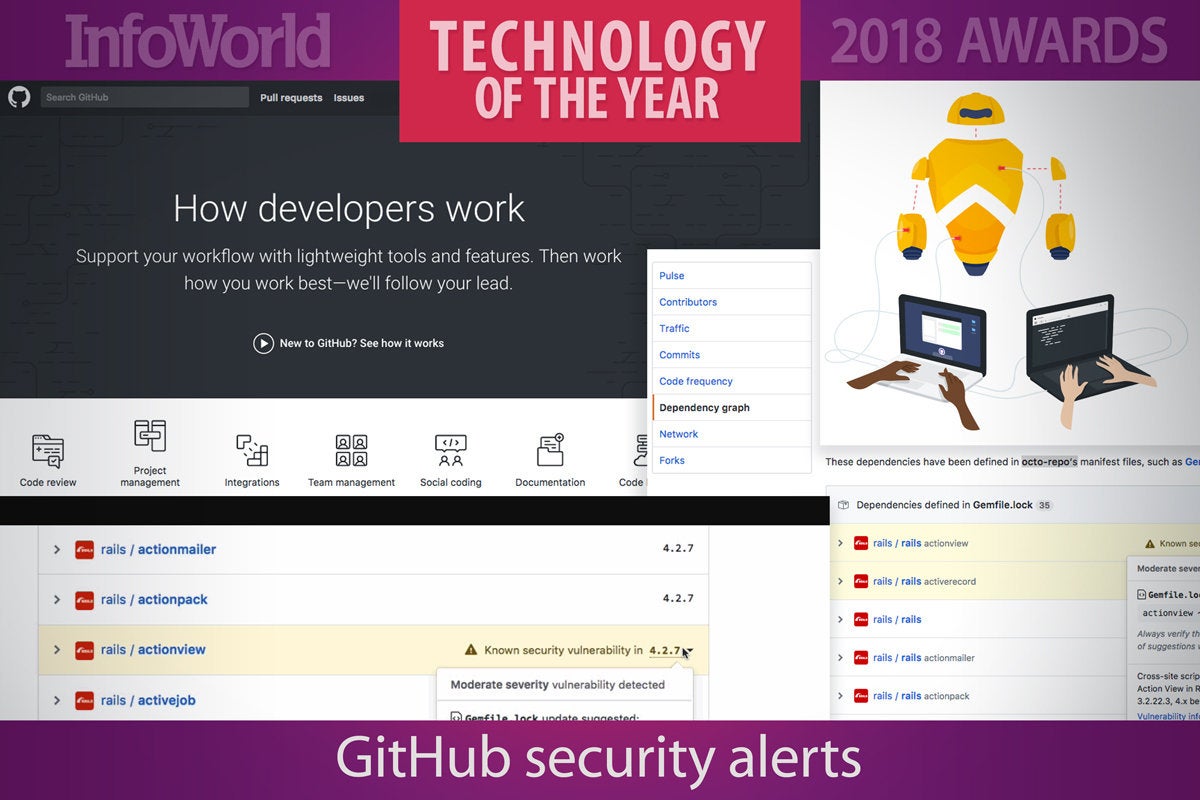
4. GitHub security alerts
Developers need security tools that integrate with their existing workflow, not complicated tools. Enter GitHub security alerts. A free service that alerts developers when their projects include dependencies that contain publicly known vulnerabilities, GitHub security alerts make it easier to build secure applications.
Developers don’t always realize how many libraries get pulled into a given software project. For example, a Node.js application can have hundreds of dependencies that weren’t explicitly included by the developer. GitHub scans all public repositories—and private repos that opt in—to generate a dependency graph for each project, or a list of its dependencies. GitHub checks the list against the public vulnerabilities in the MITRE Common Vulnerabilities and Exposures (CVE) database to identify affected components.
GitHub alerts project owners via email and web notifications with a link to the affected file, the vulnerability details, and the severity level, along with suggested steps for resolution. It is up to the project owner to fix the problem, whether by updating the component, removing the component altogether, or writing a patch to close the flaw.
GitHub currently scans only Ruby gems and NPM packages, but Python support is in the works. Considering GitHub hosts nearly 70 million repositories, and more than three-quarters of the projects have at least one dependency, we should all look forward to the scanning service becoming available to more developers.
— Fahmida Y. Rashid
5. Slack
Slack has dramatically changed the way many companies communicate. For some of us, there are days that go by without reading email. A huge part of Slack’s success is that search was always front and center in the app, right next to the actual “chat” and “view” portions of the interface. This makes Slack both a real-time communications tool and a reference platform.
Slack is now going beyond “mere” communications to serve as the circulatory system for the development organization at many companies, thanks to integrations with Jira, GitHub, and other key technologies. There are new fields of thought like chatops that combine devops with the Slack user interface.
There is still room for improvement. The new voice and video calling is miles behind Zoom and other mediums. I mean it isn’t terrible but it isn’t great yet. Also, sometimes Slack doesn’t make narrowing the search as straightforward as you’d like. Nevertheless Slack is one of those “little things” that is actually huge. It has changed the workplace forever.
— Andrew C. Oliver
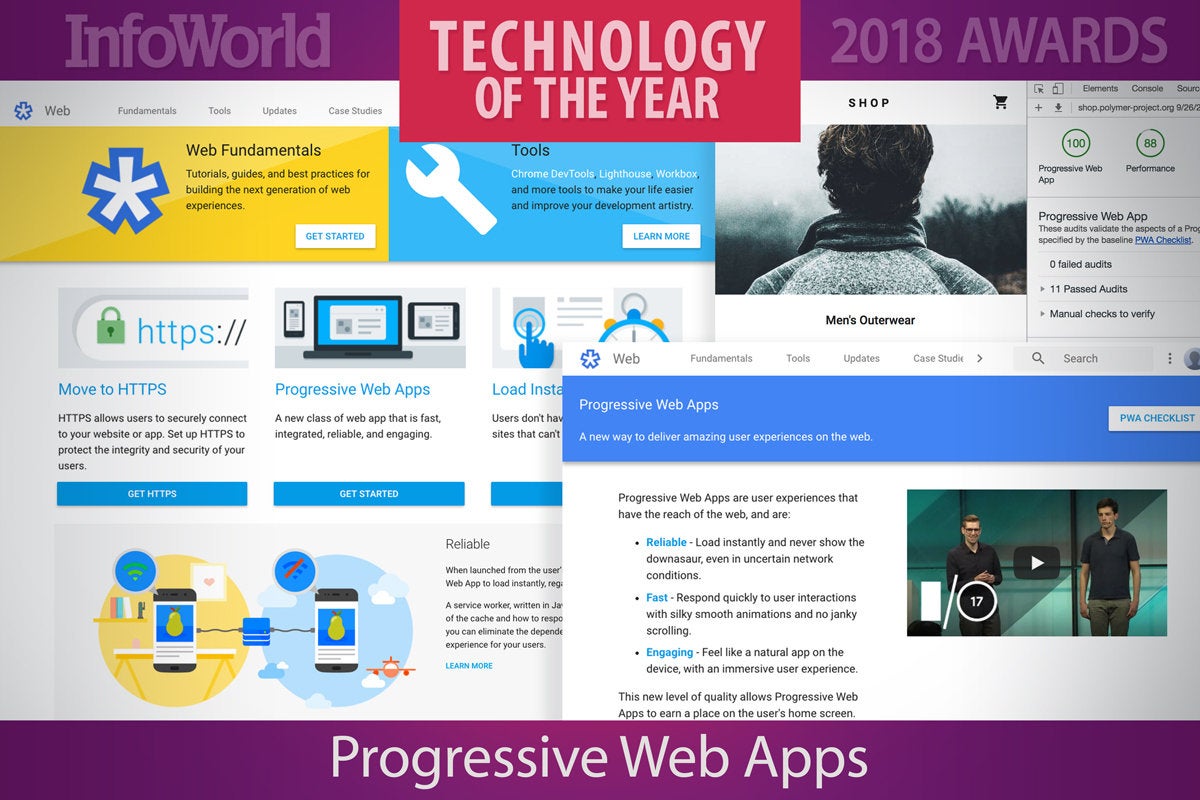
6. Progressive Web Apps
A Progressive Web App isn’t one type of thing or even a thing. It’s more a commitment to making your website as speedy and responsive as possible. And guidelines for creating a modern pile of JavaScript, CSS, and HTML that behaves well on both mobile and desktop browsers.
Proponents like Google have created documentation explaining just what they think it means to be progressive and you can use their vision as a starting point. There are a dozen or so strategies behind the code for a good web app. You’ll want to start with a small, clean framework that pops up quickly. The rest of the data can be added from background services later.
You might also make sure that common data types are marked up with special tags to help search engines find them. (Remember that Google is in the search engine business.) Products from catalogs, for instance, should come with extra tags that indicate the price, the description, and the image, all to make sure that scraping apps don’t get lost.
You can even audit your web app’s progressiveness. Google’s Chrome includes a special tab in the Developer Tools window that checks a site for many of the common requirements. You don’t need to hit everything on the list, but the more you get the better the experience will be for anyone who visits.
— Peter Wayner
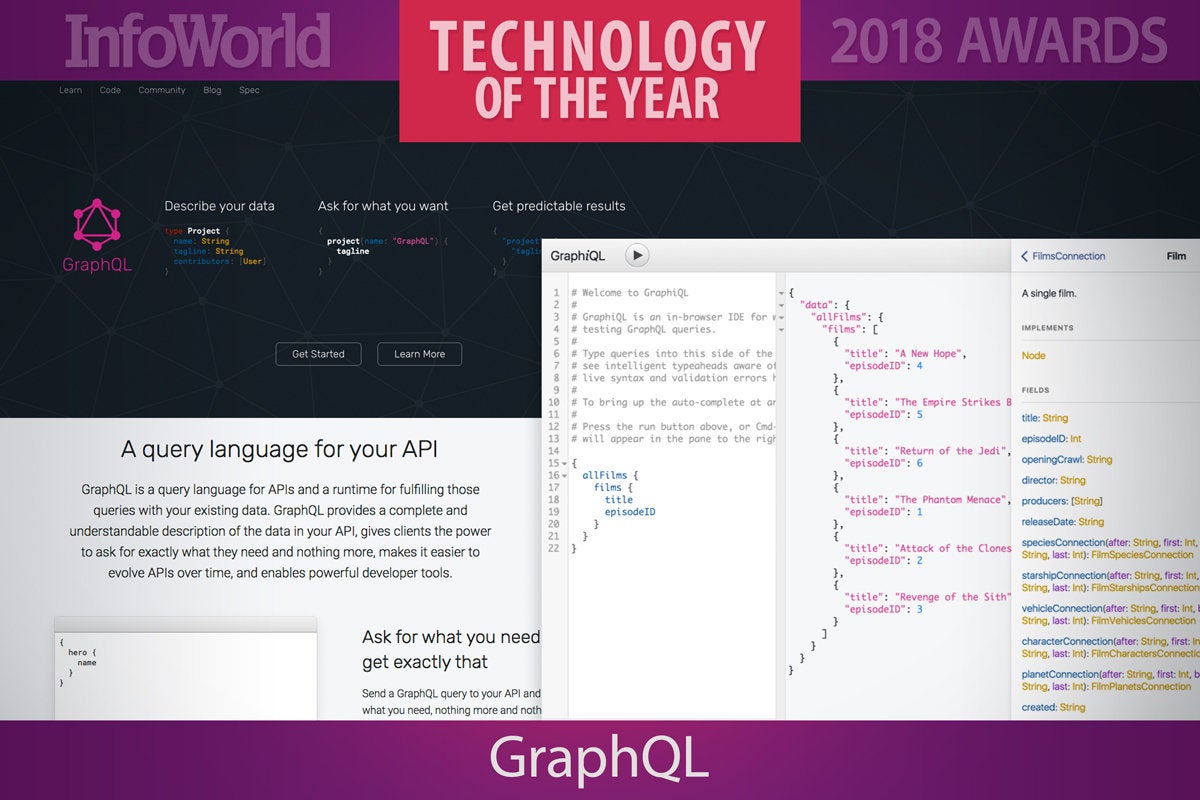
7. GraphQL
Researchers have been building databases that store graphs of nodes and connections for decades. Only within the last 10 years or so has the Internet given us so much data to store, we’ve all had to start thinking beyond the tabular world of SQL and in terms of data networks. GraphQL is a query language for the graph mindset.
Instead of juggling tables that might need to be joined, you think of data as a network of nodes. Programmers immersed in JSON data structures will feel most at home with GraphQL because a query looks something like a JSON data structure with the data left out. You specify the names of the desired fields in a nested collection of curly brackets and the database sends back a version with the data. GraphQL handles the juggling and hides much of the complexity.
GraphQL was built by Facebook, a company with more graph networks than perhaps any other. GraphQL has now morphed into an ecosystem that supports queries in dozens of languages and databases. It has become so general that it’s almost not fair to think of it as just a tool for working with graph data sets. You can use GraphQL to query pretty much anything that can be easily expressed like JSON.
— Peter Wayner
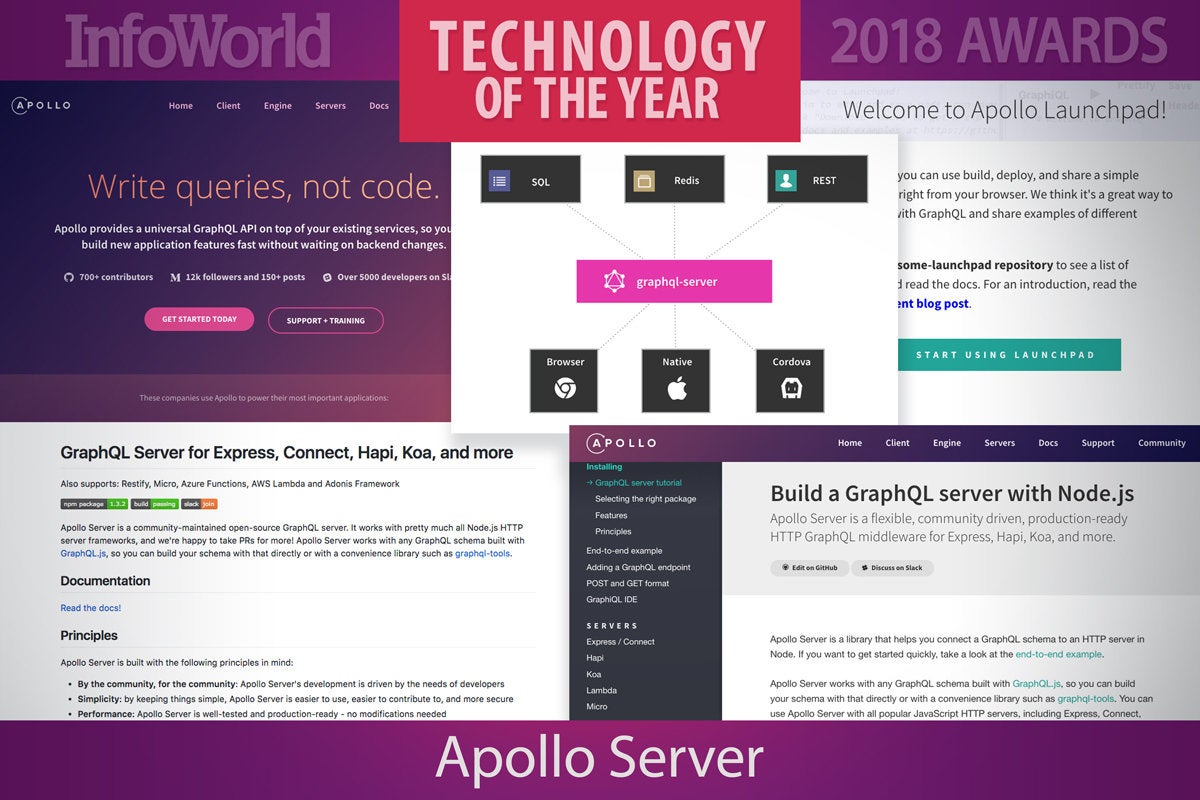
8. Apollo Server
GraphQL is an intuitive query language that drives flexible API interactions with data, but it would be nothing without a driver that understands what to do with the language. Enter Apollo Server, which became generally available in July 2017. Written for Node.js applications, Apollo Server is a GraphQL server that works for all the common web frameworks.
In a few lines of code, Apollo can add a GraphQL endpoint to an existing Node application, after which you write schemas and resolvers to handle requests from that endpoint. Those resolvers can collect and join data from backing data stores and other external locations, allowing you to abstract polyglot persistence away from the logical data model. In addition to handling the complex dance of fielding requests, determining resolvers to execute, and collecting results to return to clients, Apollo Server provides helpful developer tools such as GraphiQL, a GraphQL REPL that lives in your browser.
Apollo Data, the company behind Apollo Server, also offers Apollo Engine, a hosted suite of tools to measure and analyze performance of your queries, cache certain fields, and evaluate schema usage. Apollo Engine is free for up to one million requests per month and only requires a user account and about a dozen lines of code to set up.
— Jonathan Freeman
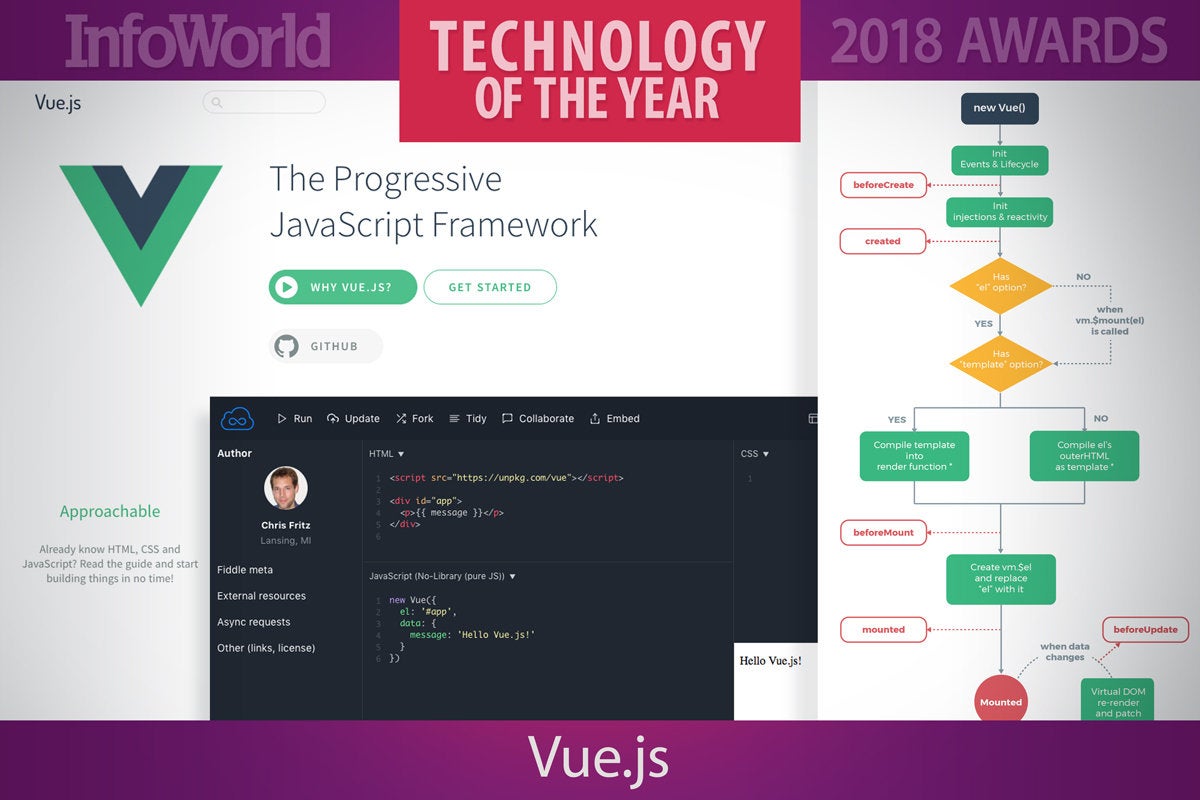
9. Vue.js
In recent years, JavaScript UI tools have been trending away from monolithic frameworks and towards smaller, component-based structures. While React has been an imposing topic in the space, its philosophical sibling, Vue.js, has nonetheless inserted itself into the conversation. Vue.js is similar to React in that it embraces the idea of components, colocates markup, functionality, and style in single files, and draws on common ancillary tools to serve other front-end responsibilities. But it’s also different in important ways.
Vue.js applications feel like a mix of Backbone.js for component definitions, Angular for templates, and a clever use of JavaScript getters and setters for managing state mutations. One of the core philosophies of Vue.js is to be progressive and accessible, so the paradigms stick close to variations on HTML, JavaScript, and CSS without introducing anything custom like JSX.
It’s no surprise then that Vue.js has a large and passionate following to rival even a library like React with strong backing by Facebook. Some JavaScript frameworks tend to be favored alongside certain back-end technologies, like Ember.js with Rails. Vue.js happens to have a large following among the Laravel community, but this flexible, approachable library goes well with just about anything.
— Jonathan Freeman
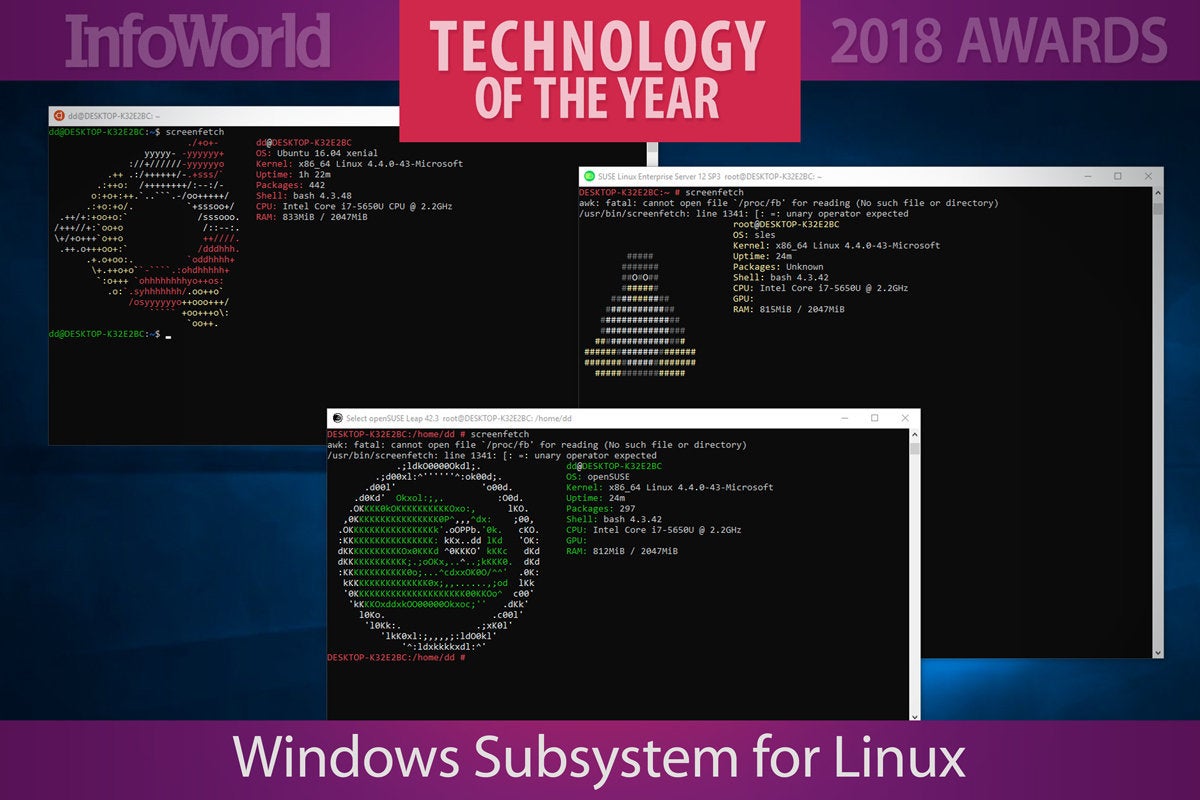
10. Windows Subsystem for Linux
If you need proof that Microsoft is serious about the cloud, look no further than the existence of the Windows Subsystem for Linux. Microsoft used to be so focused on eating the world with its operating system that anything with “interoperability” had to be one-way. Windows Subsystem for Linux gives as well as it gets: It provides a complete Linux environment and the familiar Bash shell on top of Windows. Who would have thought that Linux would be available in the Windows Store?
From inside Windows you can run your Linux stuff from Bash or actual native Linux apps. Initially available with Ubuntu, Windows Subsystem for Linux has since added support for OpenSuse and Suse Linux Enterprise Server. Fedora support is promised, but not available yet.
Microsoft intends Windows Subsystem for Linux to only run command-line stuff, though third parties have come up with hacks to run GUI apps. While you can run the Docker client inside of Windows Subsystem for Linux and manage external containers, you can’t run Docker containers (maybe too much Turducken inside of Turducken to make a lot of sense). Either way, this is a great tool for developers running Windows on the desktop who need to do Linux stuff—especially in the cloud.
— Andrew C. Oliver
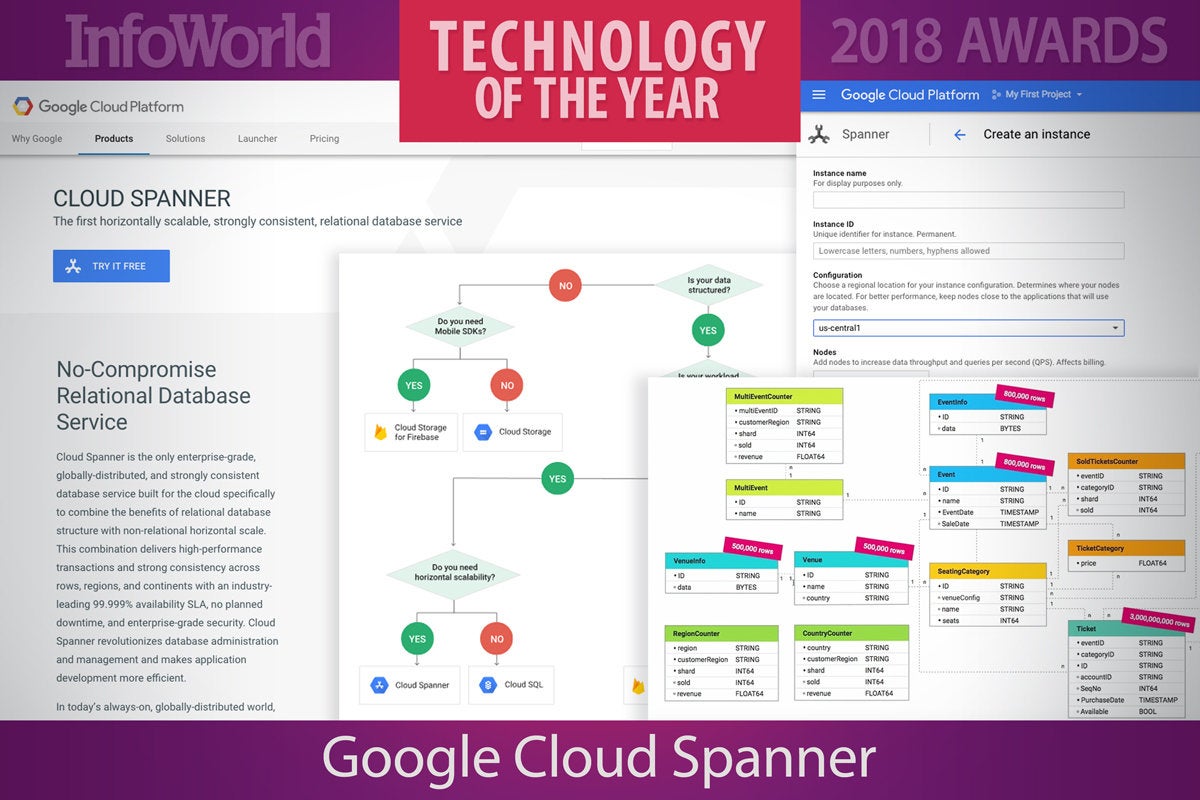
11. Google Cloud Spanner
Google Cloud Spanner is a fully managed relational database service that offers horizontal scalability for mission-critical transaction processing. It is Google’s “best of both worlds” database: It has the scalability of NoSQL databases while retaining SQL compatibility, relational schemas, ACID transactions, and external consistency. There is nothing else quite like it, although the open source CockroachDB comes close.
Essentially a sharded, globally distributed, and replicated relational database, Cloud Spanner uses a Paxos algorithm for reaching a consensus among its nodes. Client queries automatically fail over between replicas without needing to retry the query. Data is automatically re-sharded and migrated across machines as needed. Cloud Spanner relies on atomic clocks and GPS time (via the TrueTime API available in Google data centers) to keep all nodes synchronized within a tight (10ms) time window.
Everything Cloud Spanner does is designed to be inherently consistent, even at the expense of availability. Network partitions are extremely rare, however, as Cloud Spanner runs on Google’s high-availability private fiber WAN. In internal use at Google, Cloud Spanner has shown better than five nines availability. Cloud Spanner is not what you want as the storage layer for a small website or the back end of a game. It is what you want if you have a massive OLTP database that must be consistent at all times.
— Martin Heller

12. CockroachDB
CockroachDB is a distributed SQL database built on top of a transactional and consistent key-value store. Developed by ex-Googlers who were familiar with Spanner, CockroachDB uses a Spanner-inspired data storage system and draws on a Raft algorithm for reaching a consensus among its nodes. The primary design goals are support for ACID transactions, horizontal scalability, and (most of all) survivability, hence the name.
CockroachDB is designed to survive disk, machine, rack, and even data center failures with minimal latency disruption and no manual intervention. Unlike Cloud Spanner, which uses the TrueTime API available for time synchronization in Google data centers, CockroachDB can’t count on the presence of atomic clocks and GPS satellite clocks to synchronize time across nodes and data centers. It must fall back to NTP and use a more complicated scheme to ensure transactional consistency.
CockroachDB runs on Mac, Linux, and Windows operating systems, at least for development and test. Production databases usually run on Linux VMs or orchestrated containers, often hosted on public clouds in multiple data centers. CockroachDB clusters can easily scale up or down while the database continues to run. The scaling is even easier if the clusters use orchestration technology such as Kubernetes.
— Martin Heller

13. Azure Cosmos DB
Microsoft’s globe-spanning Azure Cosmos DB began life as Project Florence, an internal NoSQL store for Azure services. Now available for all to use, this multi-model cloud database takes an innovative approach to the complexities of building and managing distributed systems. Instead of supporting slow but accurate strong consistency or fast and probably inaccurate eventual consistency, Cosmos DB builds on the work of Turing Award winner Leslie Lamport to add three new consistency models suited to modern application development including the user-focused session consistency model.
Cosmos DB stores can operate globally, quickly converging to a common view of the truth, ensuring that users in the US, EU, and Asia all see the same version of the data. Users also have several different ways of working with Cosmos DB, from a JSON-based document store to a graph database queried by the Gremlin graph query language, as well as running internal JavaScript procedures on their data. Other options include support for the MongoDB APIs, making it easier to bring existing on-premises NoSQL data to the cloud. And you’re not limited to NoSQL approaches, as there is also a SQL query option and Azure’s existing Table Storage.
— Simon Bisson

14. Neo4j
In 2017 Neo4j took yet another important step in improving the flexibility and scalability of graphs in production. In years past, running a highly available Neo4j database cluster allowed you to easily distribute reads across the cluster, but required all writes to be sent to a single node. As an application developer, you were responsible for keeping track of where each node was and figuring out which queries to send where.
With the arrival of a new clustering architecture in Neo4j 3.1, users no longer have to keep track of cluster membership and roles thanks to driver-supported intelligent routing. Additionally, reads can be made safely on any node, even directly after a write thanks to “causal consistency,” an ACID-compliant tunable consistency model. Of course you can still configure read-only replicas to cluster around the core set of leader-electable nodes for even greater scale out to reduce high-traffic performance degradation.
The following release, Neo4j 3.2, brought multi data center support to the platform, enabling vast geographic distribution and peer-to-peer synchronization of read replicas. It puts a ton of heavy distributed systems theory into practice, and at the end of the day it means you can run Neo4j against larger and wider workloads.
— Jonathan Freeman
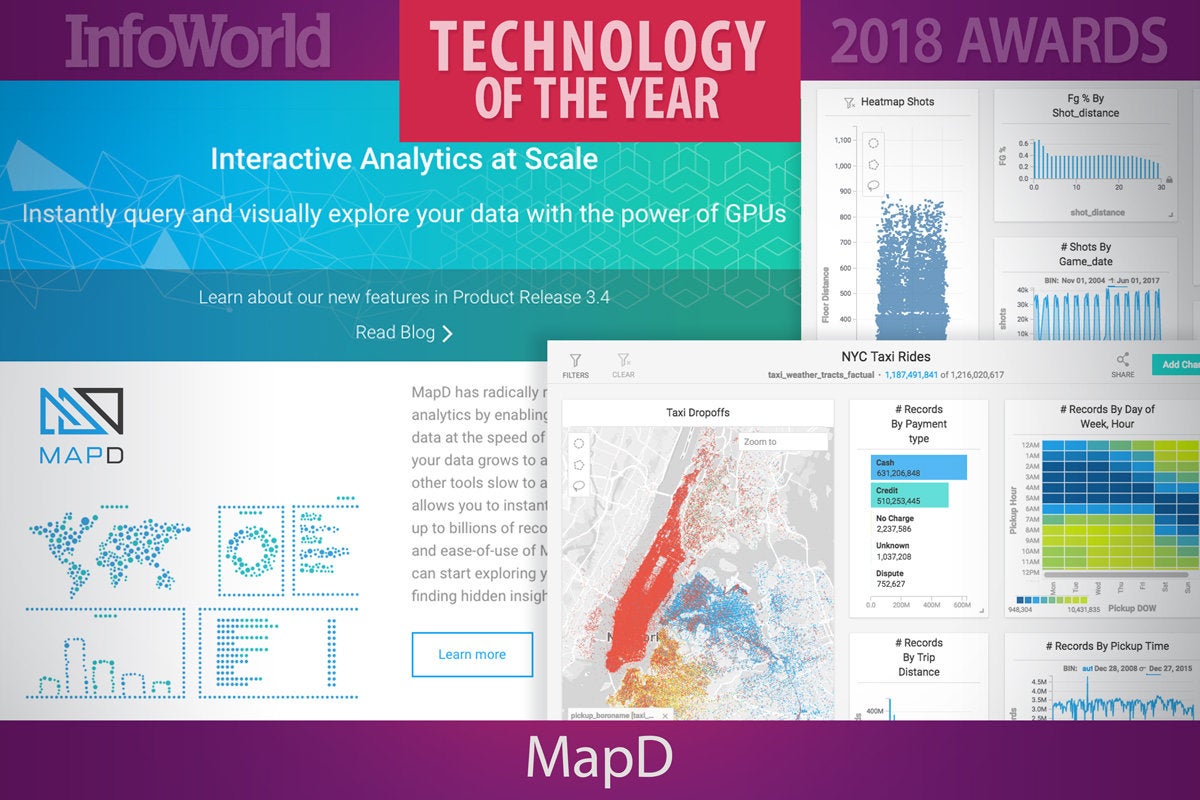
15. MapD
MapD combines an open source in-memory GPU-based SQL database with Immerse, a GPU-based visual analytics engine. MapD runs on AWS, Google Cloud Engine, and IBM Cloud.
MapD Core is an in-memory, column store, SQL relational database that was designed from the ground up to run on GPUs. The parallel processing power of GPU hardware enables the MapD Core SQL engine to query billions of rows in milliseconds using standard SQL.
The MapD Immerse visual analytics system uses the rendering engine of the MapD Core SQL engine to visualize data sets with billions of records while providing fast interactive drill-down to the individual data point level. MapD Immerse avoids the overhead of transferring large result sets from server to client, instead only sending compressed PNG images.
MapD especially shines for large-scale applications such as geospatial displays of billions (yes, with a “B”) of locations, IoT analysis with billions of devices, and log analysis with billions of events. MapD can perform these operations in milliseconds. You can run a number of MapD’s demos online.
— Martin Heller

16. Apache Spark
Apache Spark, the in-memory distributed computing and machine learning development platform, has become the de facto standard for processing data at scale, whether for querying large datasets, training machine learning models to predict future trends, or processing streaming data. While the release schedule has slowed and we’re seeing fewer tectonic shifts in the feature set, those are not necessarily bad things. We’re way past asking if Spark is usable in production. Productivity is in full force.
In 2017 it seemed every vendor embedded Spark for machine learning and stamped “Cognitive” on its product. Spark SQL has continued to fill out to where you don’t lack for many operations, and the optimizer is getting better. Structured streaming went GA. But the most active part of the project might be the MLib library for applying machine learning to data at scale. Meanwhile the ecosystem continues to expand with the development of third-party NLP libraries on top of Spark. The bottom line is Spark has continued to grow and mature—and continued to eat the world.
— Andrew C. Oliver

17. H2O.ai Driverless AI
H2O.ai Driverless AI is able to create and train good machine learning models without requiring machine learning expertise from users. It doesn’t eliminate the need for trained data scientists, but it lowers the bar for team members, eliminates most of the tedium involved in doing feature engineering, speeds up training by using multiple GPUs, and makes annotation of models possible by generating approximate statistical explanations for very exact deep learning models.
There have been at least half-a-dozen attempts to automate machine learning in the last year. In addition, there have been significant research efforts around annotation of machine learning models, usually by fitting statistical models to the results of the machine learning models. Several of these have been incorporated into Driverless AI.
Driverless AI has a goal of imitating the processes used by Kaggle grandmasters to create great deep learning models, and does a surprisingly good job. It also attempts to solve the black box problem for explaining otherwise inscrutable deep learning models by doing a cluster analysis on the data and fitting both global and cluster-local generalized linear models to the Driverless AI model prediction. The generalized linear models lend themselves to understandable interpretations: Rather than telling a loan applicant “The model says you’re a bad credit risk” you can instead report, “Your outstanding credit card debt is too high given your income, assets, and mortgage.”
— Martin Heller
18. Scikit-learn
Scikit-learn, the toolbox for machine learning in Python, stands out for its ability to get the job done, quickly and easily. Some libraries are faster and others have more algorithms, but Scikit-learn is a “go-to” tool of choice for any Python developer incorporating machine learning into practical applications today. Built on Python’s scientific computing packages, NumPy and SciPy, Scikit-learn is ubiquitous and thoroughly documented. It is one of the best places to start with machine learning.
Scikit-learn doesn’t yet support PyPy, the fast just-in-time compiling Python implementation, because its dependencies NumPy and SciPy don’t fully support PyPy. But rarely a day goes by without a contribution to the project. For applications that require more speed there is integration to BLAS for linear algebra. If I had to choose one machine learning toolkit for my company, Scikit-learn would be it. Easy to learn and use, with a wide assortment of well-established algorithms, Scikit-learn will keep you on the rails, with little diversion, and integrate well into existing infrastructure.
— Steven Nuñez
19. R programming language
The R ecosystem offers the widest selection of high-quality algorithms among the machine learning tools. Dating back more than 25 years, the R programming language is stable, well-tested, and supported by first-rate tools like RStudio, RCloud, and R Notebooks. Remarkably, for a pure-statistics programming language, R currently ranks number eight in the Tiobe index of programming language popularity. If you could describe a lens through which to view R, it would be “academic.” If Scikit-learn is a practical construction worker who gets the job done, and TensorFlow is the hipster geek, R is the tweedy professor.
No matter what the machine learning problem, there is likely a solution in CRAN, the comprehensive repository for R code—and it was undoubtedly written by an expert in the domain. There is a price to pay for this: R takes some getting used too. It is not a terribly difficult hill to climb, and you won’t lack for learning resources or an active and helpful community, but R syntax is different from that of many other programming languages. Now supported directly in the likes of Apache Spark, Microsoft SQL Server, and Greenplum, R can be incorporated into real applications more easily than ever.
— Steven Nuñez
20. TensorFlow
Machine learning is a complex discipline. Data engineers embrace any tool, any system that eases the process of acquiring data, training models, serving predictions, and refining future results. Google’s TensorFlow lets developers build machine learning and neural network solutions using the high-level languages they’re familiar with, and without sacrificing performance—even when using “slow” languages like Python.
Google brought TensorFlow to a version 1.0 release in early 2017, but didn’t stop there. Google also unveiled TensorFlow Mobile and TensorFlow Lite, versions of the framework that run on hardware with limited CPU and memory. Several new sections of the TensorFlow library offer interfaces—including Keras—that require less programming to create and train models. A third-party project, TensorFire, even makes it possible to execute TensorFlow models in a web browser, complete with GPU acceleration.
What Google wants most with TensorFlow in the long run, though, is to lay the groundwork for an end-to-end machine learning environment. For instance, the Tensor2Tensor project is a Python library for creating and managing workflows in TensorFlow. Data sets, problems, models, hyperparameters, and trainers can all be managed by way of high-level code instead of recreated ad hoc.
— Serdar Yegulalp
21. PyTorch
Facebook’s PyTorch has had a spectacular year. The first public beta only just arrived in February 2017, and yet the Python-based deep learning framework has already emerged as a serious rival to Google’s TensorFlow, especially in the research space. Indeed, popular online courses such as fast.ai have gone as far as re-writing their entire curriculum in PyTorch.
The major difference between PyTorch and TensorFlow is that TensorFlow takes a static, more declarative approach to building neural networks: You define your model and then have TensorFlow “compile” that code into a computational graph. This makes dynamic networks harder to work with in TensorFlow because you have to recompile the graph each time you alter the network. Plus the compilation process is opaque to the developer, which can make debugging TensorFlow networks awkward.
Instead of static compilation, PyTorch dynamically creates your graph structure at runtime, allowing you to update your model at will with almost no performance penalty. This imperative, Pythonic approach to building and training models is not only more flexible than static evaluation, but also makes debugging so much more intuitive.
— Ian Pointer
22. Kotlin
Kotlin is a general purpose, open source, statically typed “pragmatic” programming language for the JVM and Android that combines object-oriented and functional programming features. It is focused on interoperability, safety, clarity, and tooling support.
At first glance, Kotlin looks like a streamlined version of Java. It is that, but it’s also a full-blown functional programming language, with higher-order functions, anonymous functions, lambdas, inline functions, closures, tail regression, and generics. And it’s still an object-oriented language, which makes porting Java classes simple.
Kotlin was designed to eliminate the danger of null pointer references and streamline the handling of null values. It does this by making a null illegal for standard types, adding nullable types, and implementing shortcut notations to handle tests for null.
In most cases, calling Java code from Kotlin works the way you might expect. For example, any time both getters and setters exist in a Java class, Kotlin treats them as properties with the same name. Kotlin can also be transpiled to JavaScript ES5.1. A version of Kotlin that generates native code is in the works.
— Martin Heller
23. Rust
There may never be a one-size-fits-everything programming language, but at least we can count on having best-of-breed languages for specific problem domains. Rust set out to be just that—the best of breed—for bare-metal and systems-level programming, with smarter approaches to memory safety than C and C++ but also with no garbage collection or standalone runtime.
No, the plan isn’t to convince everyone to rewrite all existing C and C++ software in Rust, but rather to develop Rust as an attractive long-term alternative. Over the course of 2017, Rust took several steps in that direction, such as delivering tools to provide live feedback to programmers directly from the Rust compiler.
If you were looking for a high-profile, real-world use case for Rust, one landed in 2017. Rust was long intended to allow Mozilla to rewrite key components of Firefox for speed, and the November 2017 update to Firefox included the first major Rust component—a parallel CSS engine that draws on Rust’s “fearless concurrency” to speed up page styling.
— Serdar Yegulalp
24. Signal Sciences
Security vendors tend to focus on solving very specific problems, leaving IT teams scrambling to daisy-chain tools together to address broader concerns. Traditional application security, for example, relies on web application firewalls (WAF) and runtime application security protection (RASP) to protect applications from certain types of attacks. However, these protections don’t scale well for containerized applications or keep up with the rapid pace of development and deployment in devops environments.
Signal Sciences is different. Its Web Protection Platform not only addresses the entire spectrum of web-based threats, but is designed to protect all manner of modern application software: web applications, microservices, and APIs across any language, on any cloud or container, within any physical infrastructure or PaaS/IaaS environment. The platform defends against account takeover, application-level distributed-denial-of-service attacks, business logic attacks, and attacks targeting issues listed in the OWASP Top 10.
The Web Protection Platform comes with more than a dozen single-click integrations with security and operations tools, including Atlassian JIRA, Datadog, PagerDuty, Slack,
and Splunk. Another plus: As more customers are added to the platform, all customers gain more visibility into the different types of attacks and how they are remediated. Everyone benefits from a bigger community.
— Fahmida Y. Rashid

25. Microsoft Project Olympus
The Open Compute Project’s open hardware standards have done much to push forward the development of cloud-scale hardware. By sharing designs for connectors, racks, servers, switches, and storage hardware, the OCP has defined a new generation of data center technologies and made them widely available – and able to be manufactured at the scale the big public clouds need.
Project Olympus is one of Microsoft’s open hardware designs, shared with OCP members and driven as an open design project with multiple forks of Microsoft’s initial spec. Built around the OCP’s Universal Motherboard specification, Project Olympus is a flexible compute server, with support for Intel, AMD, and ARM64 processors as well as FPGA, GPGPU, and other specialized silicon to add features as needed.
The initial Project Olympus hardware has been joined by a second, deeper chassis design, the Project Olympus Hyperscale GPU Accelerator. The “HGX-1” hosts eight Pascal-class Nvidia GPUs for machine learning workloads. Four HGX-1 servers can be linked together via Nvidia’s NVLink to give you up to 32 GPUS, ideal for complex workloads.
Cloud data centers need lots of hardware, but workloads are moving away from the one-size-fits-all x86 server. The flexible Project Olympus design allows the same chassis to support different motherboards and thus handle the varied workloads running on modern cloud infrastructures. And as it’s open hardware, it can be produced by any manufacturer, ensuring wide availability and low prices.
— Simon Bisson
Copyright © 2018 IDG Communications, Inc.